ANNOVAR (2): 关于注释数据库
使用 ANNOVAR 来注释基因组中的突变,首先要下载 ANNOVAR 的注释数据库。如果你需要经常地更新注释数据库,又或者你是“不更新会死星人”,想使用最新的数据库,那么这篇文章也许对你有帮助。
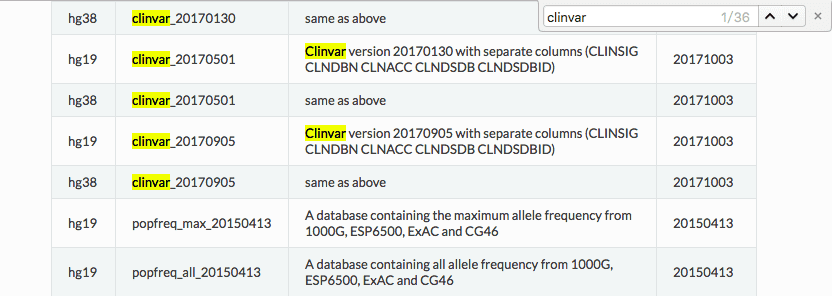
除此之外,ANNOVAR 的注释数据库更新一般会改正一些错误,比如17年10月的一次数据库更新,改正了以前长期存在的 Clinvar 数据库中,同一个 SNP 多种 allele 都注释到同一个突变中的问题,因此使用新的数据库有时也是必要的。

如何下载 ANNOVAR 注释数据库
ANNOVAR 中自带下载注释数据库的程序,使用的方法是:
- 先到Download ANNOVAR查找自己需要的数据库,例如Clinvar,找到最新的clinvar_20170905
- 然后使用命令
annotate_variation.pl -buildver hg19 -downdb -webfrom annovar clinvar_20170905 humandb/ - 程序会自动下载该数据库以及索引并解压到humandb文件夹
这样做的好处是 ANNOVAR 会自动将下载好的数据库进行解压,并放到指定的文件夹;但是注释数据库文件的服务器在国外,如果遇到网络不好的情况,经常性地会断开,又要重新下载一遍;并且 ANNOVAR 的程序下载注释数据库是一条命令一个的,十分不方便。
手动下载 ANNOVAR 注释数据库
前面提到过,ANNOVAR 下载注释数据库的命令是一次一个,非常不友好;而且身处国内,有时网络又不好,可不可以手动批量下载 ANNOVAR 的注释数据库,答案是当然的。
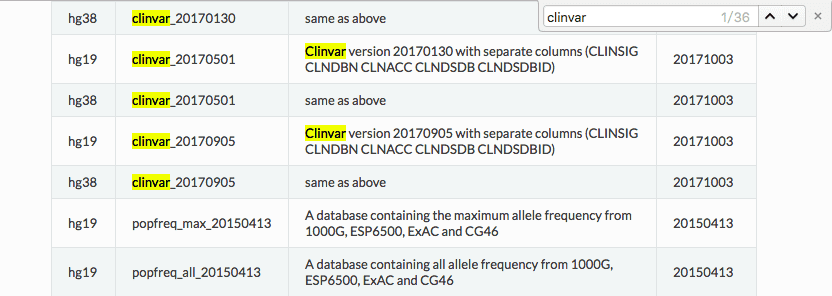
ANNOVAR 可以使用命令annotate_variation.pl -buildver hg19 -downdb -webfrom annovar avdblist humandb/来获得可供下载的注释数据库的清单,运行该命令后我们可以获得名为hg19_avdblist.txt的文件,查看该文件我们可以看见所有 hg19版本的注释数据库。该文件分为3列,分别为数据库文件名称、发布日期以及文件大小。
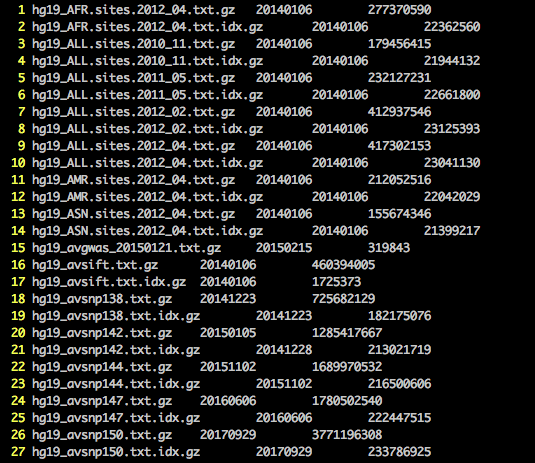
我们观察 ANNOVAR 下载注释数据库时的log如下

可以看见,ANNOVAR的注释数据库下载地址都是http://www.openbioinformatics.org/annovar/download/后面接上需要下载的注释数据库名称(在上图所示的hg19_avdblist.txt文件可以获得),之所以需要下载hg19_avdblist.txt文件是因为http://www.openbioinformatics.org/annovar/download/这个地址无法直接 wget 镜像全站。
由此,我们可以使用 wget或 curl 手动下载注释数据库,例如
wget -P humandb/ http://www.openbioinformatics.org/annovar/download/hg19_clinvar_20170905.txt.gz
wget -P humandb/ http://www.openbioinformatics.org/annovar/download/hg19_clinvar_20170905.txt.idx.gz # 别忘记需要下载注释数据库的 Index
cd humandb/
gzip -d hg19_clinvar_20170905.txt.gz # 下载完后需要解压才能使用
gzip -d hg19_clinvar_20170905.txt.idx.gz或者直接将需要下载的地址写到一个文件中,然后运行wget -c -i download.txt来批量下载。
订阅 ANNOVAR 更新
ANNOVAR 的注释数据库一般更新得比较慢,而且不定期,如果我们想定期了解 ANNOVAR 注释数据库更新了哪些,甚至是 ANNOVAR 的更新,是不是需要每隔一段时间去查看一次呢?
当然不需要,我们可以使用第三方的服务,只要Kai Wang更新,我们就能收到提醒。

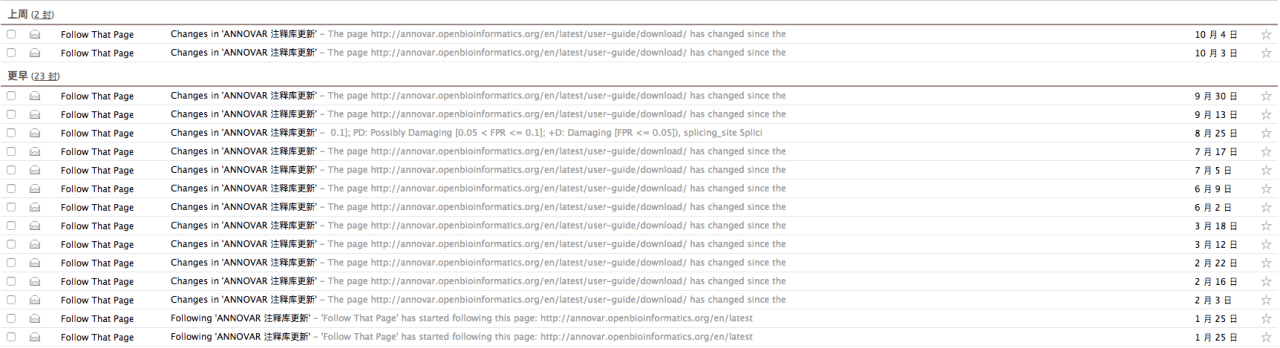
上图我们可以清晰地看到,ANNOVAR 更新了 Clinvar 数据库的注释数据库,从2016年的03月份的版本更新到了17年的10月份的版本,时间跨度这么久,如果人力去监控,肯定费时费力。
但是我们可以使用Follow That Page这个服务,注册该网站后,填写需要监控的页面如http://annovar.openbioinformatics.org/en/latest/user-guide/download/(ANNOVAR 的注释数据库页面)以及扫描频率(一天一次足矣),我们就可以接收邮件提醒,及时了解 ANNOVAR 的更新。

Follow That Page 这个服务免费而且非常稳定,我已经使用了这个服务3年多时间,用来追踪 ANNOVAR 的更新也已经1年多,只要 ANNOVAR 更新,我就能收到提醒;而且这个网站同理可以用来追踪其他的网站,比如某些政府网站的政策公布,这种不定期、没有RSS源而又十分重要的资讯,Follow That Page 可谓屡试不爽。
脚本自动更新
前面我们提到 ANNOVAR 的程序不友好,一次下载一个注释数据库;后面订阅了数据库更新后还是要手动去更新。
为了解决这个问题,我们可以设置一个定时任务,让服务器自动去更新注释数据库了;实现的原理通过比对新旧两者的hg19_avdblist.txt内容,我们能够得到修改的数据库;实现方式类似于Git diff,我是用了 Linux 系统自带的 diff 命令。以下代码仅为演示,请大家根据需求进行优化。
cp hg19_avdblist.txt old_hg19_avdblist.txt #备份旧的数据库列表
annotate_variation.pl -buildver hg19 -downdb -webfrom annovar avdblist ./ #下载新的数据库列表
diff -c old_hg19_avdblist.txt hg19_avdblist.txt \
| grep -E '^\+|^\!' | cut -f1 \
| sed "s/\! /http\:\/\/www\.openbioinformatics\.org\/annovar\/download\//g;s/\+ /http\:\/\/www\.openbioinformatics\.org\/annovar\/download\//g" > download.txt #获取修改过的数据库,写入 download.txt
wget -c -i download.txt #下载数据库
将以上命令设置为定时执行,就可以自动更新 ANNOVAR 的注释数据库了。
以上内容,如果有误或者有好的 idea,欢迎大家留言,谢谢。
